
{kind=link}
[ad_1]

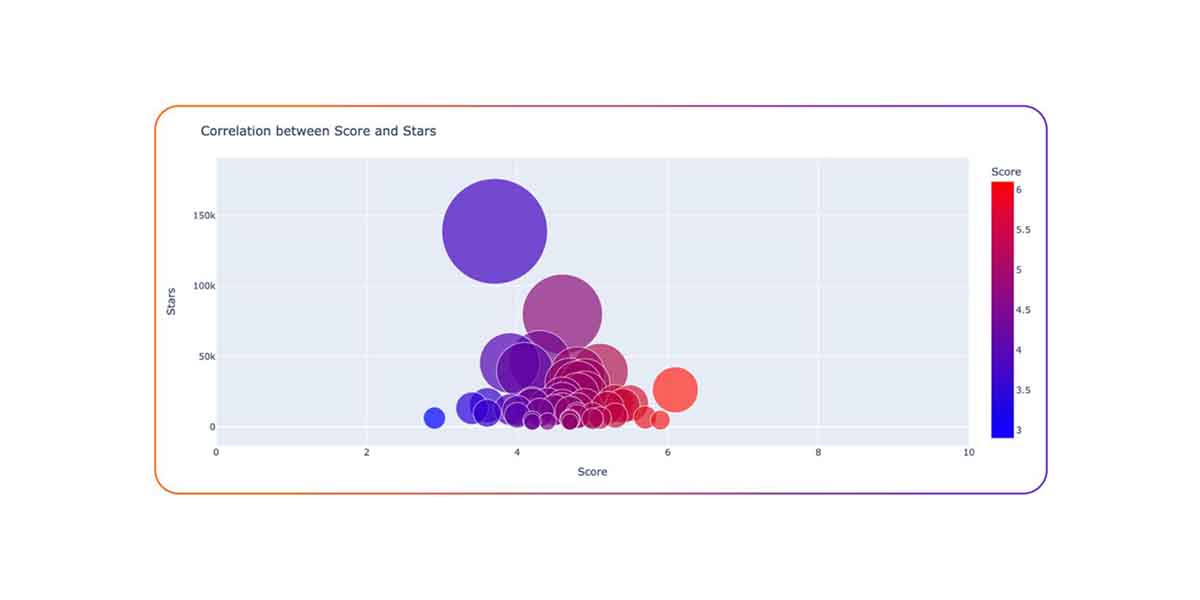
There may be a number of curiosity in integrating generative AI and different synthetic intelligence purposes into current software program merchandise and platforms. Nevertheless, these AI tasks are pretty new and immature from a safety standpoint, which exposes organizations utilizing these purposes to numerous safety dangers, in line with current evaluation by software program provide chain safety firm Rezilion.Since ChatGPT’s debut earlier this yr, there at the moment are greater than 30,000 open supply tasks utilizing GPT 3.5 on GitHub, which highlights a severe software program provide chain concern: how safe are these tasks which are being built-in left and proper?Rezilion’s staff of researchers tried to reply that query by analyzing 50 hottest Massive Language Mannequin (LLM)-based tasks on GitHub – the place recognition was measured by what number of stars the challenge has. The challenge’s safety posture was measured by the OpenSSF Scorecard rating. The Scorecard device from the Open Supply Safety Basis assesses the challenge repository on numerous components such because the variety of vulnerability it has, how ceaselessly the code is being maintained, what dependencies it depends on, and the presence of binary information, to calculate the Scorecard rating. The upper the quantity, the safer the code.The researchers mapped the challenge’s recognition (measurement of the bubble, y-axis) and safety posture (x-axis). Not one of the tasks analyzed scored greater than 6.1, which signifies that there was a excessive degree of safety threat related to these tasks, Rezilion stated. The common rating was 4.6 out of 10, indicating that the tasks had been riddled with points. Actually, the most well-liked challenge (with nearly 140,000 stars), Auto-GPT, is lower than three months previous and has the third-lowest rating of three.7, making it a particularly dangerous challenge from a safety perspective.When organizations are contemplating which open supply tasks to combine into their codebase or which of them to work with, they think about components equivalent to whether or not the challenge is steady, presently supported and actively maintained, and the variety of individuals actively engaged on the challenge. There are a number of kinds of dangers organizations have to contemplate, equivalent to belief boundary dangers, information administration dangers, and inherent mannequin dangers.”When a challenge is new, there are extra dangers across the stability of the challenge, and it’s too quickly to inform whether or not the challenge will hold evolving and stay maintained,” the researchers wrote of their evaluation. “Most tasks expertise robust development of their early years earlier than hitting a peak in neighborhood exercise because the challenge reaches full maturity, then the extent of engagement tends to stabilize and stay constant.”The age of the challenge was related, Rezilion researchers stated, noting that a lot of the tasks within the evaluation had been between two and 6 months previous. When the researchers checked out each the age of the challenge and Scorecard rating, the age-score mixture that was the most typical was tasks which are two months previous and have a Scorecard rating of 4.5 to five.”Newly-established LLM tasks obtain fast success and witness exponential development when it comes to recognition,” the researchers stated. “Nevertheless, their Scorecard scores stay comparatively low.”Growth and safety groups want to grasp the dangers related to adopting any new applied sciences, and make a follow of evaluating them prior to make use of.
[ad_2]