
{kind=link}
[ad_1]
Congratulations to Tao Chen, Jie Xu and Pulkit Agrawal who’ve gained the CoRL 2021 greatest paper award!
Their work, A system for basic in-hand object re-orientation, was extremely praised by the judging committee who commented that “the sheer scope and variation throughout objects examined with this methodology, and the vary of various coverage architectures and approaches examined makes this paper extraordinarily thorough in its evaluation of this reorientation job”.
Beneath, the authors inform us extra about their work, the methodology, and what they’re planning subsequent.
What’s the subject of the analysis in your paper?
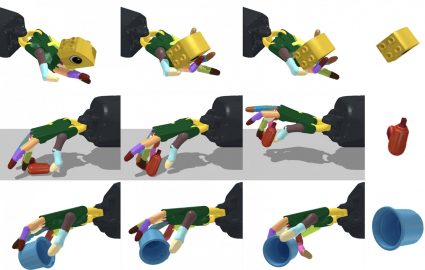
We current a system for reorienting novel objects utilizing an anthropomorphic robotic hand with any configuration, with the hand dealing with each upwards and downwards. We reveal the aptitude of reorienting over 2000 geometrically totally different objects in each circumstances. The realized controller also can reorient novel unseen objects.
Might you inform us in regards to the implications of your analysis and why it’s an fascinating space for research?
Our realized ability (in-hand object reorientation) can allow quick pick-and-place of objects in desired orientations and areas. For instance, in logistics and manufacturing, it’s a widespread demand to pack objects into slots for kitting. Presently, that is often achieved by way of a two-stage course of involving re-grasping. Our system will be capable of obtain it in a single step, which might considerably enhance the packing pace and increase the manufacturing effectivity.
One other software is enabling robots to function a greater variety of instruments. The most typical end-effector in industrial robots is a parallel-jaw gripper, partially as a consequence of its simplicity in management. Nevertheless, such an end-effector is bodily unable to deal with many instruments we see in our each day life. For instance, even utilizing pliers is troublesome for such a gripper because it can not dexterously transfer one deal with backwards and forwards. Our system will permit a multi-fingered hand to dexterously manipulate such instruments, which opens up a brand new space for robotics functions.
Might you clarify your methodology?
We use a model-free reinforcement studying algorithm to coach the controller for reorienting objects. In-hand object reorientation is a difficult contact-rich job. It requires an incredible quantity of coaching. To hurry up the training course of, we first practice the coverage with privileged state info corresponding to object velocities. Utilizing the privileged state info drastically improves the training pace. Apart from this, we additionally discovered that offering initialization on the hand and object pose is crucial for coaching the controller to reorient objects when the hand faces downward. As well as, we develop a method to facilitate the coaching by constructing a curriculum on gravitational acceleration. We name this method “gravity curriculum”.
With these strategies, we’re capable of practice a controller that may reorient many objects even with a downward-facing hand. Nevertheless, a sensible concern of the realized controller is that it makes use of privileged state info, which could be nontrivial to get in the actual world. For instance, it’s onerous to measure the thing’s velocity in the actual world. To make sure that we will deploy a controller reliably in the actual world, we use teacher-student coaching. We use the controller educated with the privileged state info because the trainer. Then we practice a second controller (pupil) that doesn’t depend on any privileged state info and therefore has the potential to be deployed reliably in the actual world. This pupil controller is educated to mimic the trainer controller utilizing imitation studying. The coaching of the scholar controller turns into a supervised studying downside and is due to this fact sample-efficient. Within the deployment time, we solely want the scholar controller.
What had been your major findings?
We developed a basic system that can be utilized to coach controllers that may reorient objects with both the robotic hand dealing with upward or downward. The identical system will also be used to coach controllers that use exterior assist corresponding to a supporting floor for object re-orientation. Such controllers realized in our system are strong and also can reorient unseen novel objects. We additionally recognized a number of strategies which are vital for coaching a controller to reorient objects with a downward-facing hand.
A priori one may consider that it’s important for the robotic to learn about object form so as to manipulate new shapes. Surprisingly, we discover that the robotic can manipulate new objects with out figuring out their form. It means that strong management methods mitigate the necessity for advanced perceptual processing. In different phrases, we’d want a lot easier perceptual processing methods than beforehand thought for advanced manipulation duties.
What additional work are you planning on this space?
Our rapid subsequent step is to attain such manipulation abilities on an actual robotic hand. To realize this, we might want to sort out many challenges. We’ll examine overcoming the sim-to-real hole such that the simulation outcomes could be transferred to the actual world. We additionally plan to design new robotic hand {hardware} by means of collaboration such that all the robotic system could be dexterous and low-cost.
In regards to the authors
Tao Chen is a Ph.D. pupil within the Unbelievable AI Lab at MIT CSAIL, suggested by Professor Pulkit Agrawal. His analysis pursuits revolve across the intersection of robotic studying, manipulation, locomotion, and navigation. Extra lately, he has been specializing in dexterous manipulation. His analysis papers have been revealed in high AI and robotics conferences. He acquired his grasp’s diploma, suggested by Professor Abhinav Gupta, from the Robotics Institute at CMU, and his bachelor’s diploma from Shanghai Jiao Tong College.
Jie Xu is a Ph.D. pupil at MIT CSAIL, suggested by Professor Wojciech Matusik within the Computational Design and Fabrication Group (CDFG). He obtained a bachelor’s diploma from Division of Laptop Science and Expertise at Tsinghua College with honours in 2016. Throughout his undergraduate interval, he labored with Professor Shi-Min Hu within the Tsinghua Graphics & Geometric Computing Group. His analysis primarily focuses on the intersection of Robotics, Simulation, and Machine Studying. Particularly, he’s within the following subjects: robotics management, reinforcement studying, differentiable physics-based simulation, robotics management and design co-optimization, and sim-to-real.
Dr Pulkit Agrawal is the Steven and Renee Finn Chair Professor within the Division of Electrical Engineering and Laptop Science at MIT. He earned his Ph.D. from UC Berkeley and co-founded SafelyYou Inc. His analysis pursuits span robotics, deep studying, pc imaginative and prescient and reinforcement studying. Pulkit accomplished his bachelor’s at IIT Kanpur and was awarded the Director’s Gold Medal. He’s a recipient of the Sony College Analysis Award, Salesforce Analysis Award, Amazon Machine Studying Analysis Award, Signatures Fellow Award, Fulbright Science and Expertise Award, Goldman Sachs World Management Award, OPJEMS, and Sridhar Memorial Prize, amongst others.
Discover out extra
Learn the paper on arXiv.
The movies of the realized insurance policies can be found right here, as is a video of the authors’ presentation at CoRL.
Learn extra in regards to the profitable and shortlisted papers for the CoRL awards right here.
tags: Algorithm AI-Cognition, c-Analysis-Innovation
Lucy Smith
is Managing Editor for AIhub.
[ad_2]