
{kind=link}
[ad_1]
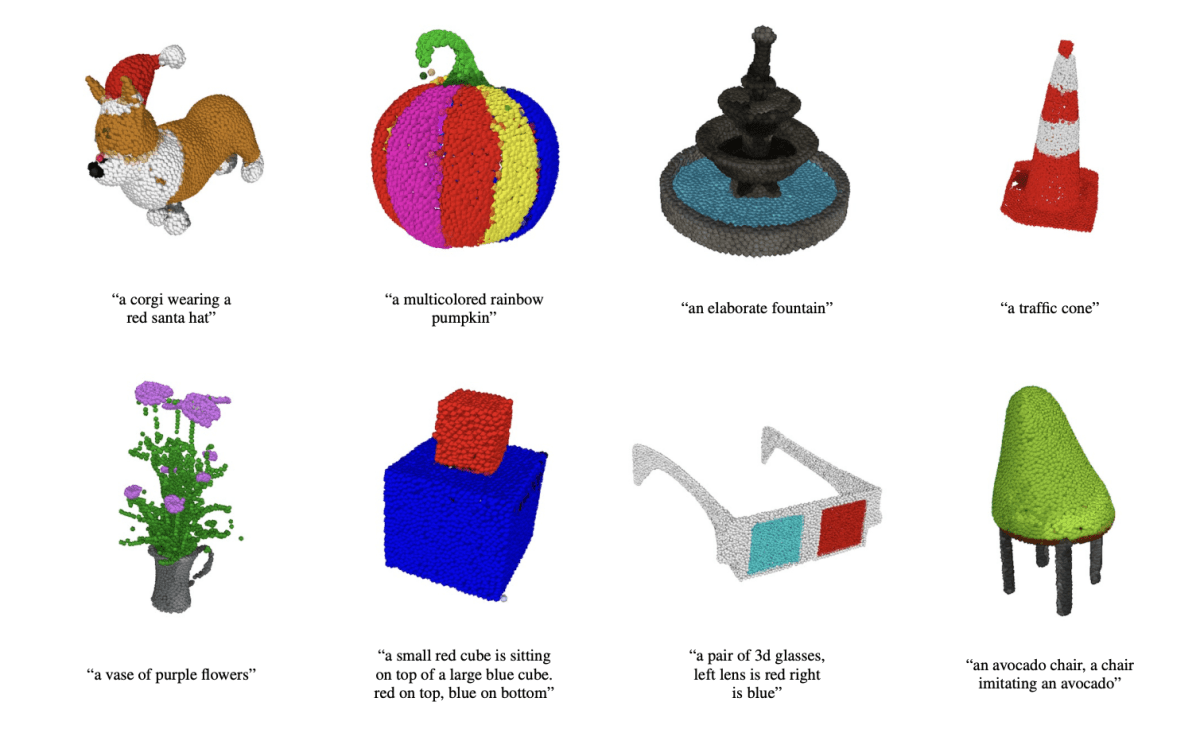
The following breakthrough to take the AI world by storm could be 3D mannequin mills. This week, OpenAI open-sourced Level-E, a machine studying system that creates a 3D object given a textual content immediate. In accordance with a paper printed alongside the code base, Level-E can produce 3D fashions in 1 to 2 minutes on a single Nvidia V100 GPU.
Level-E doesn’t create 3D objects within the conventional sense. Relatively, it generates level clouds, or discrete units of knowledge factors in area that symbolize a 3D form — hency the cheeky abbreviation. (The “E” in Level-E is brief for “effectivity,” as a result of it’s ostensibly sooner than earlier 3D object era approaches.) Level clouds are simpler to synthesize from a computational standpoint, however they don’t seize an object’s fine-grained form or texture — a key limitation of Level-E presently.
To get round this limitation, the Level-E workforce skilled an extra AI system to transform Level-E’s level clouds to meshes. (Meshes — the collections of vertices, edges and faces that outline an object — are generally utilized in 3D modeling and design.) However they notice within the paper that the mannequin can typically miss sure elements of objects, leading to blocky or distorted shapes.
Picture Credit: OpenAI
Outdoors of the mesh-generating mannequin, which stands alone, Level-E consists of two fashions: a text-to-image mannequin and an image-to-3D mannequin. The text-to-image mannequin, just like generative artwork methods like OpenAI’s personal DALL-E 2 and Secure Diffusion, was skilled on labeled photographs to know the associations between phrases and visible ideas. The image-to-3D mannequin, alternatively, was fed a set of photographs paired with 3D objects in order that it realized to successfully translate between the 2.
When given a textual content immediate — for instance, “a 3D printable gear, a single gear 3 inches in diameter and half inch thick” — Level-E’s text-to-image mannequin generates an artificial rendered object that’s fed to the image-to-3D mannequin, which then generates some extent cloud.
After coaching the fashions on an information set of “a number of million” 3D objects and related metadata, Level-E might produce coloured level clouds that ceaselessly matched textual content prompts, the OpenAI researchers say. It’s not good — Level-E’s image-to-3D mannequin typically fails to know the picture from the text-to-image mannequin, leading to a form that doesn’t match the textual content immediate. Nonetheless, it’s orders of magnitude sooner than the earlier state-of-the-art — a minimum of in line with the OpenAI workforce.
Changing the Level-E level clouds into meshes.
“Whereas our methodology performs worse on this analysis than state-of-the-art methods, it produces samples in a small fraction of the time,” they wrote within the paper. “This might make it extra sensible for sure functions, or might permit for the invention of higher-quality 3D object.”
What are the functions, precisely? Nicely, the OpenAI researchers level out that Level-E’s level clouds could possibly be used to manufacture real-world objects, for instance by way of 3D printing. With the extra mesh-converting mannequin, the system might — as soon as it’s just a little extra polished — additionally discover its approach into sport and animation growth workflows.
OpenAI could be the newest firm to leap into the 3D object generator fray, however — as alluded to earlier — it definitely isn’t the primary. Earlier this 12 months, Google launched DreamFusion, an expanded model of Dream Fields, a generative 3D system that the corporate unveiled again in 2021. Not like Dream Fields, DreamFusion requires no prior coaching, that means that it could possibly generate 3D representations of objects with out 3D knowledge.
Whereas all eyes are on 2D artwork mills at this time, model-synthesizing AI could possibly be the following huge trade disruptor. 3D fashions are broadly utilized in movie and TV, inside design, structure and numerous science fields. Architectural corporations use them to demo proposed buildings and landscapes, for instance, whereas engineers leverage fashions as designs of latest units, automobiles and constructions.
Level-E failure circumstances.
3D fashions often take some time to craft, although — wherever between a number of hours to a number of days. AI like Level-E might change that if the kinks are sometime labored out, and make OpenAI a good revenue doing so.
The query is what kind of mental property disputes may come up in time. There’s a big marketplace for 3D fashions, with a number of on-line marketplaces together with CGStudio and CreativeMarket permitting artists to promote content material they’ve created. If Level-E catches on and its fashions make their approach onto the marketplaces, mannequin artists may protest, pointing to proof that trendy generative AI borrow closely from its coaching knowledge — present 3D fashions, in Level-E’s case. Like DALL-E 2, Level-E doesn’t credit score or cite any of the artists that may’ve influenced its generations.
However OpenAI’s leaving that challenge for one more day. Neither the Level-E paper nor GitHub web page make any point out of copyright.
To their credit score, the researchers do point out that they count on Level-E to undergo from different issues, like biases inherited from the coaching knowledge and an absence of safeguards round fashions that could be used to create “harmful objects.” That’s maybe why they’re cautious to characterize Level-E as a “start line” that they hope will encourage “additional work” within the discipline of text-to-3D synthesis.
[ad_2]