
{kind=link}
[ad_1]
How can we make a robotic be taught in the actual world whereas making certain security? On this work, we present the way it’s attainable to face this drawback. The important thing thought to use area data and use the constraint definition to our benefit. Following our strategy, it’s attainable to implement studying robotic brokers that may discover and be taught in an arbitrary setting whereas making certain security on the identical time.
Security and studying in robots
Security is a elementary characteristic in real-world robotics functions: robots mustn’t trigger injury to the setting, to themselves, they usually should guarantee the protection of individuals working round them. To make sure security after we deploy a brand new software, we wish to keep away from constraint violation at any time. These stringent security constraints are troublesome to implement in a reinforcement studying setting. That is the explanation why it’s onerous to deploy studying brokers in the actual world. Classical reinforcement studying brokers use random exploration, resembling Gaussian insurance policies, to behave within the setting and extract helpful data to enhance job efficiency. Nevertheless, random exploration might trigger constraint violations. These constraint violations should be prevented in any respect prices in robotic platforms, as they typically lead to a serious system failure.
Whereas the robotic framework is difficult, additionally it is a really well-known and well-studied drawback: thus, we are able to exploit some key outcomes and data from the sector. Certainly, typically a robotic’s kinematics and dynamics are recognized and may be exploited by the educational methods. Additionally, bodily constraints e.g., avoiding collisions and imposing joint limits, may be written in analytical type. All this data may be exploited by the educational robotic.
Our strategy
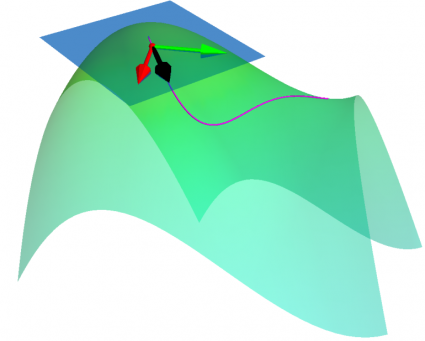
Many reinforcement studying approaches attempt to clear up the protection drawback by incorporating the constraint data within the studying course of. This strategy typically ends in slower studying performances, whereas not having the ability to guarantee security throughout the entire studying course of. As a substitute, we current a novel perspective to the issue, introducing ATACOM (Appearing on the TAngent area of the COnstraint Manifold). Completely different from different state-of-the-art approaches, ATACOM tries to create a protected motion area wherein each motion is inherently protected. To take action, we have to assemble the constraint manifold and exploit the fundamental area data of the agent. As soon as we’ve got the constraint manifold, we outline our motion area because the tangent area to the constraint manifold.
We will assemble the constraint manifold utilizing arbitrary differentiable constraints. The one requirement is that the constraint operate should rely solely on controllable variables i.e. the variables that we are able to instantly management with our management motion. An instance could possibly be the robotic joint positions and velocities.
We will assist each equality and inequality constraints. Inequality constraints are notably essential as they can be utilized to keep away from particular areas of the state area or to implement the joint limits. Nevertheless, they don’t outline a manifold. To acquire a manifold, we remodel the inequality constraints into equality constraints by introducing slack variables.
With ATACOM, we are able to guarantee security by taking motion on the tangent area of the constraint manifold. An intuitive technique to see why that is true is to think about the movement on the floor of a sphere: any level with a velocity tangent to the sphere itself will preserve shifting on the floor of the sphere. The identical thought may be prolonged to extra advanced robotic methods, contemplating the acceleration of system variables (or the generalized coordinates, when contemplating a mechanical system) as a substitute of velocities.
The above-mentioned framework solely works if we take into account continuous-time methods, when the management motion is the instantaneous velocity or acceleration. Sadly, the overwhelming majority of robotic controllers and reinforcement studying approaches are discrete-time digital controllers. Thus, even taking the tangent path of the constraint manifold will lead to a constraint violation. It’s at all times attainable to cut back the violations by growing the management frequency. Nevertheless, error accumulates over time, inflicting a drift from the constraint manifold. To unravel this subject, we introduce an error correction time period that ensures that the system stays on the reward manifold. In our work, we implement this time period as a easy proportional controller.Lastly, many robotics methods can’t be managed instantly by velocity or accelerations. Nevertheless, if an inverse dynamics mannequin or a monitoring controller is on the market, we are able to use it and compute the right management motion.
Outcomes
We tried ATACOM on a simulated air hockey job. We use two various kinds of robots. The primary one is a planar robotic. On this job, we implement joint velocities and we keep away from the collision of the end-effector with desk boundaries.The second robotic is a Kuka Iiwa 14 arm. On this situation, we constrained the end-effector to maneuver on the planar floor and we guarantee no collision will happen between the robotic arm and the desk.In each experiments, we are able to be taught a protected coverage utilizing the Delicate Actor-Critic algorithm as a studying algorithm together with the ATACOM framework. With our strategy, we’re capable of be taught good insurance policies quick and we are able to guarantee low constraint violations at any timestep. Sadly, the constraint violation can’t be zero resulting from discretization, however it may be diminished to be arbitrarily small. This isn’t a serious subject in real-world methods, as they’re affected by noisy measurements and non-ideal actuation.
Is the protection drawback solved now?
The important thing query to ask is that if we are able to guarantee any security ensures with ATACOM. Sadly, this isn’t true on the whole. What we are able to implement are state constraints at every timestep. This features a vast class of constraints, resembling fastened impediment avoidance, joint limits, floor constraints. We will prolong our technique to constraints contemplating not (instantly) controllable variables. Whereas we are able to guarantee security to a sure extent additionally on this situation, we can’t be sure that the constraint violation won’t be violated throughout the entire trajectory. Certainly, if the not controllable variables act in an adversarial method, they may discover a long-term technique to trigger constraint violation in the long run. A straightforward instance is a prey-predator situation: even when we be sure that the prey avoids every predator, a bunch of predators can carry out a high-level technique and entice the agent in the long run.
Thus, with ATACOM we are able to guarantee security at a step degree, however we’re not in a position to make sure long-term security, which requires reasoning at trajectory degree. To make sure this type of security, extra superior strategies shall be wanted.
Discover out extra
The authors had been greatest paper award finalists at CoRL this 12 months, for his or her work: Robotic reinforcement studying on the constraint manifold.
Learn the paper.
The GitHub web page for the work is right here.
Learn extra concerning the successful and shortlisted papers for the CoRL awards right here.
tags: c-Analysis-Innovation
Puze Liu
is a PhD scholar within the Clever Autonomous Techniques Group, Technical College Darmstadt
Puze Liu
is a PhD scholar within the Clever Autonomous Techniques Group, Technical College Darmstadt
Davide Tateo
is a Postdoctoral Researcher on the Clever Autonomous Techniques Laboratory within the Pc Science Division of the Technical College of Darmstadt
Davide Tateo
is a Postdoctoral Researcher on the Clever Autonomous Techniques Laboratory within the Pc Science Division of the Technical College of Darmstadt
Haitham Bou-Ammar
leads the reinforcement studying workforce at Huawei applied sciences Analysis & Improvement UK and is an Honorary Lecturer at UCL
Haitham Bou-Ammar
leads the reinforcement studying workforce at Huawei applied sciences Analysis & Improvement UK and is an Honorary Lecturer at UCL
Jan Peters
is a full professor for Clever Autonomous Techniques on the Technische Universitaet Darmstadt and a senior analysis scientist on the MPI for Clever Techniques
Jan Peters
is a full professor for Clever Autonomous Techniques on the Technische Universitaet Darmstadt and a senior analysis scientist on the MPI for Clever Techniques
[ad_2]